N.B. added dataset and link to Datalore Notebooks.
Benchmarking is notourusly hard, hence I know these results are not fully show-casing possibilities of the JVM. Nontheless, they’re results.
Benchmark Details
- Pre-downloaded CSV (dataset: Plotly All Stocks 5 Years)
- Use Eager-API as Kotlin DataFrame does not have a Lazy API (this would help
polarsfurther) - Run 10k times to make sure the JVM isn’t a slow starter (one should do this even better using JMH and their API to benchmark)
Results
The results speak clearly.
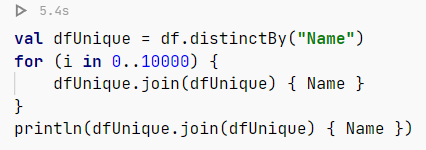
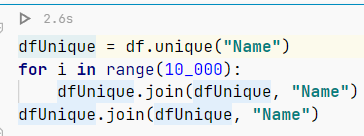
polarsis 2x faster (!).polarsuses 1GB less RAM.polarsactually downloaded the same CSV file 12x faster, and caches the result internally unlike Kotlin for later instant usage.
Thoughts
I think it’s interesting to see how much faster polars is, even if I use eager API and don’t use any fancy feature(s) like groupBy that’s optimized like crazy.
It really showcases what a powerhouse Rust is to run intensive applications with, and now I’m left wondering if perhaps one should wrap polars on the JVM. 🤓 This has been done for other platforms, such as NodeJS, R & Elixir.
Wrapping Rust from the JVM isn’t easy today though, but with the new progress with Project Panama it should be easier. Project Panama introduces a simpler, safer and more efficient way to call Native code from the JVM through the Foreign Function & Memory API. I expect it to become even better as it’s currently only in preview… 😉
That’s all for now.
~Hampus