from IPython.display import clear_output
# ⚠️Add the Kaggle lines if not running on Kaggle⚠️
#!pip install kaggle --upgrade
#!kaggle kernels pull lundet/yelp-reviews
!pip install -U pyarrow sentence-transformers plotly polars ydata-profiling setfit bpemb yake pigeonXT-jupyter
clear_output()Installing Python Packages
We install a few libraries to assist us.
NLP: sentence-transformers (simple efficient sentence embeddings), setfit (few-shot training) & bpemb (fast efficient subword embeddings).
Data: polars (fast and sane DataFrame) & ydata-profiling (data profiling).
Other: pigeonXT-jupyter (annotation/labeling inside jupyter) & yake (keyword extraction).
Introduction
This notebook-blog is adapted from my Yelp Reviews notebook on Kaggle.
In this notebook I was show-case a way to easily extract real valuable insights from Yelp Reviews using Few-Shot Learning. The dataset contains 5.2 million reviews and 174,000 businesses and is available here.
To create value from reviews we need to structurally find things not cleanly available in the data, i.e. classifying the “Stars” (1-5) isn’t that valuable value as the data already exist, unless we wish to find invalid reviews.
I chose to extract actionable feedback to improve a restaurant business, which is valuable to a owner.
I had a few other ideas in mind, but to keep the the blog short & to the point of SetFit I move remaining tasks and Data Analysis into Appendices at the end. The other task include Topic Classification/Tagging to extract patterns and Keyword Extraction.
SetFit what is it?
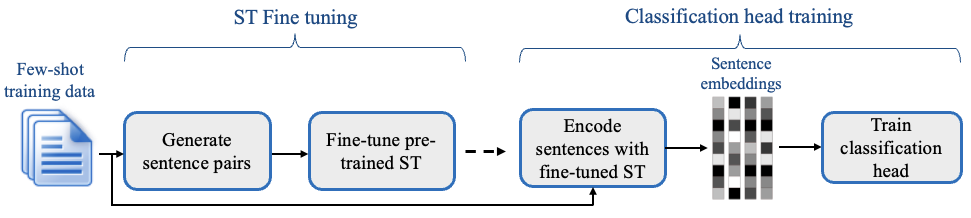
SetFit is an efficient and prompt-free framework for few-shot fine-tuning of Sentence Transformers. It achieves high accuracy with little labeled data - for instance, with only 8 labeled examples per class on the Customer Reviews sentiment dataset, SetFit is competitive with fine-tuning RoBERTa Large on the full training set of 3k examples 🤯!
Compared to other few-shot learning methods, SetFit has several unique features:
- 🗣 No prompts or verbalisers: Current techniques for few-shot fine-tuning require handcrafted prompts or verbalisers to convert examples into a format that’s suitable for the underlying language model. SetFit dispenses with prompts altogether by generating rich embeddings directly from text examples.
- 🏎 Fast to train: SetFit doesn’t require large-scale models like T0 or GPT-3 to achieve high accuracy. As a result, it is typically an order of magnitude (or more) faster to train and run inference with.
- 🌎 Multilingual support: SetFit can be used with any Sentence Transformer on the Hub, which means you can classify text in multiple languages by simply fine-tuning a multilingual checkpoint.
Above is excerpt from github.com/huggingface/setfit
Explain like I’m Five (ELI5)
SetFit builds a larger dataset of sentence similarity by using pairs of sentences (permutations), we fine-tune our embeddings based on the similarity.
Finally we fine-tune a classification head using the fine-tuned embeddings on the original data.
ELI10
SetFit works by first finetuning a pretrained sentence-transformer (ST) on a small number of text pairs, in a contrastive Siamese manner. The resulting model is then used to generate rich text embeddings, which are used to train a classification head.
This is a simpler competitor to PEFT which requires complicated prompts and very large LLM’s.
During the first phase of fine-tuning the ST we enlarge the few-shot dataset into a bigger one using a contrastive approach which means that the dataset is expanded using the following method:
- Sample \(R\) set of Positive triplets,
{a, b, 1}- a & b are sentences with class C.
- Sample \(R\) set of Negative triplets,
{c, d, 0}- c is class C, d is another class
- Produce dataset T by concatenating the positive and negative triplets
\(T = 2R*C\)
Where C is the number of classes. \(R\) is chosen to be \(20\) in the paper.
The grand idea is that we generate these sentence pairs which we can then fine-tune the model on as Positive or Negative in similarities by using the Siamese style of network and sentence similarity.
The second step then fine-tunes a Classification Head on the original labeling, embedding the sentences using the ST fine-tuned in the first step.
Classifying Review as Helpful or Not
I’m excited to get started! To find if a review is Helpful or Not, that is if it has actionable feedback or not is interesting.
The data is not available out of the box, but using SetFit we only need 8+ labels per class to achieve State-of-the-Art performance!
Keeping things simple, and lazy, I make it a binary classifier with the classes Improvements & None.
To see the Data Analysis go to Appendix.
How many reviews do we have?
import polars as pl
df_review_all = pl.scan_ndjson("/kaggle/input/yelp-dataset/yelp_academic_dataset_review.json") # scan, once again lazy.
"Number of reviews", df_review_all.select(pl.count()).collect(streaming=True)[0,0]('Number of reviews', 6990280)Selecting the most reviewed business as our choice, this is easily done in a lazy manner keeping RAM low.
max_reviewed_business = df_review_all.groupby("business_id").count().sort("count", descending=True).limit(1).collect()[0, "business_id"]
df_review = df_review_all.filter(pl.col("business_id") == max_reviewed_business).collect()Annotating/Labeling the data
This is easily done using pigeonXT. Please note that the labeling widgets are not visible anymore because once the notebook is shut down the widgets stops working.
I counteract the manual labeling by keeping the labels in a list in the cell after.
Anyhow, I sample 40 items which I label depending if the feedback is helpful improvements or not helpful.
import pigeonXT as pixt
review_sample = df_review["text"].sample(n=40, seed=42).to_list()
labels = ['Improvements', 'None', ]
annotations = pixt.annotate(
review_sample,
options=labels
)Unfortunately widgets cannot be saved in a notebooks state, as such you can’t see my labeling.
Additionally to make the notebook easily re-executable I add manual labels based on the result just underneath 👇
# Saving manually because each session removes annotations
annotation_labels = ['None', 'None', 'None', 'None', 'Improvements', 'None', 'Improvements', 'None', 'None', 'None', 'None', 'None', 'None', 'Improvements', 'None', 'Improvements', 'None', 'Improvements', 'Improvements', 'Improvements', 'None', 'None', 'None', 'None', 'Improvements', 'Improvements', 'None', 'None', 'None', 'None', 'Improvements', 'None', 'None', 'None', 'None', 'Improvements', 'None', 'Improvements', 'None', 'None']
annotation_labels = [0 if x == 'None' else 1 for x in annotation_labels]Train/Eval split
We extract seven (7) reviews as holdout (eval_df) to evaluate model on. This eval_df has a few samples of each class.
import pandas as pd
df = pd.DataFrame({"text": review_sample, "label": annotation_labels})
train_df = df[:-7]
eval_df = df[-7:]Training using SetFit
To train our model using SetFit we need to instantiate a Trainer, just like you do with HuggingFace Transformers.
We also need to use a sentence-transformer-model, I choose MiniLM because it’s very capable while small. Additionally we need to sample our dataset (sample_dataset) to make sure we have equal number of samples of each class, the default being n=8 per class.
Finally I annotated the params directly in the code 🤓
from IPython.display import clear_output
from setfit import SetFitModel, SetFitTrainer, sample_dataset
from sentence_transformers.losses import CosineSimilarityLoss
from datasets import Dataset
train_ds = Dataset.from_pandas(train_df)
train_ds_sampled = sample_dataset(train_ds, label_column="label")
eval_ds = Dataset.from_pandas(eval_df)
model = SetFitModel.from_pretrained(
"sentence-transformers/all-MiniLM-L6-v2",
)
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_ds_sampled,
eval_dataset=eval_ds,
loss_class=CosineSimilarityLoss, # CosineSimilarty as a loss function on ST fine-tuning
batch_size=16,
# contrastive learning is explained earlier
num_iterations=20, # Number of text pairs to generate for contrastive learning
num_epochs=1 # Number of epochs to use for contrastive learning
)
clear_output()Now training is as simple as trainer.train() and then we can evaluate the model using trainer.evaluate()!
trainer.train(batch_size=8)
metrics = trainer.evaluate();metrics***** Running training *****
Num examples = 640
Num epochs = 1
Total optimization steps = 80
Total train batch size = 8***** Running evaluation *****{'accuracy': 1.0}Wow! 🤯
1.0 accuracy on the 7 reviews in the evaluation dataset, that’s amazing!
…How about a custom test?
model([
"I'd like the portions to be larger and the tables are very small. The food otherwise is pretty good!",
"The food is simply amazing! A must go!"
])tensor([1, 0])1 = Improvement, 0 = None
Evaluation
This model performs incredibly well! We have 100% accuracy on Eval Dataset and it correctly predict handwritten reviews! 🤯
It’s an amazing feat that the fine-tuning require this few labels to perform this well, which additionally means it trains super fast! All in all, with this tool we can easily:
- Label few samples (8+ per class)
- Train model
- Run model inference
Resulting in a custom classifier that can extract high value data from unstructured data, in an instant!
In this case we make it possible to extract all reviews that contains Helpful Improvements/Actionable Feedback suggested by Reviewers.
My mind is blown away!
Ending Thoughts
I believe we can make the application more powerful by rather doing few-shot Named Entity Recognition (NER). This way we’d tag the exact span that has actionable feedback, rather than the full reviews.
This would of course require token-by-token labeling which I was to lazy to do in my free time… 😅
Even without a NER I think the results are impressive and has good impact.
All in all I think this excercise shows how far Large Language Models (LLM’s) have gotten outside the ChatGPT bubble, and they’re darn powerful. Using a smaller LLM (MiniLM is 91 MB (!)) also provides new possibilities like running the model on-the-edge, directly at the users hands which simplifies questions about uploading data among others.
Appendix
Here I add the Data Analysis & other tasks I scratched (keyword & topic clustering).
Appendix A: Data Understanding & Analysis
To understand the data we should read the data documentation at yelp.com. The data is split into 5 files.
- Review, 2. Check-In, 3. Business, 4. User & 5. Tip
And file-names (yelp_academic_dataset=*): ['Dataset_User_Agreement.pdf','*_review.json', '*_checkin.json', '*_business.json', '*_tip.json', '*_user.json']
To understand the data I think we’d like to know the size, how the data looks like and some other quick analysis.
Using LLM’s we don’t need to clean it as much but it’s still a good excercise of value to understand your data deeper.
Data Analysis: Reviews
import polars as pl
df_review_all = pl.scan_ndjson("/kaggle/input/yelp-dataset/yelp_academic_dataset_review.json") # scan, once again lazy.
"Number of reviews", df_review_all.select(pl.count()).collect(streaming=True)[0,0]('Number of reviews', 6990280)That’s a lot of reviews, we should probably sample fewer to examine.
Making use of pl.LazyFrame we make sure to read the full dataset, but rather we do take_every which means we skip loading 999/1000 rows, later sampling \(1000\) of the final dataset.
df_review_sample = df_review_all.take_every(1_000).collect().sample(n=1_000, seed=42)
print(df_review_sample.schema)
"Review: ", df_review_sample[0, "text"]{'review_id': Utf8, 'user_id': Utf8, 'business_id': Utf8, 'stars': Float64, 'useful': Int64, 'funny': Int64, 'cool': Int64, 'text': Utf8, 'date': Utf8}('Review: ',
'First timer, came with my boyfriend and they took a while to seat us. Same problem with getting our orders, very slow service. Although the food was great. Found this place because of the Axxcess card. Brought the bill without us asking, felt like I was being rushed. Ignored that we wanted to us the offer from the card, had to get our bill red printed. Overall, the food was good, cannot say the same about the service.')The review isn’t the nicest, but it’s at least the full text and very informative. That’s great for text applications!
In the sample of data I personally examined ~50 to make sure I understand what makes a review Helpful or Not.
Data Analysis: Business
We should view the other files too, to validate what the data contains and so on.
Let’s use pl.LazyFrame.limit to make sure we only read 3 samples and never open the rest of the data.
df_business = pl.scan_ndjson("/kaggle/input/yelp-dataset/yelp_academic_dataset_business.json")
df_business.limit(3).collect()
shape: (3, 14)
| business_id | name | address | city | state | postal_code | latitude | longitude | stars | review_count | is_open | attributes | categories | hours |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| str | str | str | str | str | str | f64 | f64 | f64 | i64 | i64 | struct[33] | str | struct[7] |
| "Pns2l4eNsfO8kk… | "Abby Rappoport… | "1616 Chapala S… | "Santa Barbara" | "CA" | "93101" | 34.426679 | -119.711197 | 5.0 | 7 | 0 | {"True",null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null} | "Doctors, Tradi… | {null,null,null,null,null,null,null} |
| "mpf3x-BjTdTEA3… | "The UPS Store" | "87 Grasso Plaz… | "Affton" | "MO" | "63123" | 38.551126 | -90.335695 | 3.0 | 15 | 1 | {null,"True",null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null} | "Shipping Cente… | {"0:0-0:0","8:0-18:30","8:0-18:30","8:0-18:30","8:0-18:30","8:0-14:0",null} |
| "tUFrWirKiKi_TA… | "Target" | "5255 E Broadwa… | "Tucson" | "AZ" | "85711" | 32.223236 | -110.880452 | 3.5 | 22 | 0 | {"False","True","True","2","False","False","False","False","u'no'","{'garage': False, 'street': False, 'validated': False, 'lot': True, 'valet': False}","True","False","False","False","False","False",null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null} | "Department Sto… | {"8:0-22:0","8:0-22:0","8:0-22:0","8:0-22:0","8:0-23:0","8:0-23:0","8:0-22:0"} |
Interesting, there’s a lot of things we don’t really care about. But stars & review_count is relevant.
So which restaurant has the most stars? What is their count?
df_business.sort("review_count", descending=True).select(["business_id", "stars", "review_count"]).limit(3).collect()
shape: (3, 3)
| business_id | stars | review_count |
|---|---|---|
| str | f64 | i64 |
| "_ab50qdWOk0DdB… | 4.0 | 7568 |
| "ac1AeYqs8Z4_e2… | 4.0 | 7400 |
| "GXFMD0Z4jEVZBC… | 4.5 | 6093 |
The most reviewed business has 7.5k reviews (!) and is averaging 4 stars, which is pretty great!
I’ll later choose this restaurant as the basis of my “Helpful” or “Not Helpful” review.
Ydata-Profiler Analysis
The business data is pretty tabular, as such I’d like to try ydata-profiling which is an automated data analysis tool which extracts some good statistics. It’s like DataFrame.describe() on steroids!
report = ProfileReport(df_business.drop(["name", "city", "is_open", "categories", "latitude", "longitude", "attributes", "hours", "business_id", "address"]).take_every(500).collect().to_pandas())
report.to_widgets()Because widgets are removed we don’t see, but trust me when I say that the only thing we find is a high correlation between review_count and state which doesn’t give us a lot as we sampled the dataset.
Let’s extract our review dataset of the most common restaurant!
b_id = df_business.sort("review_count", descending=True).select(["business_id"]).limit(1).collect()[0,0]
df_review = df_review_all.filter(pl.col("business_id") == b_id).collect(streaming=True)
df_review.head()
shape: (5, 9)
| review_id | user_id | business_id | stars | useful | funny | cool | text | date |
|---|---|---|---|---|---|---|---|---|
| str | str | str | f64 | i64 | i64 | i64 | str | str |
| "vHLTOsdILT7xgT… | "417HF4q8ynnWtu… | "_ab50qdWOk0DdB… | 5.0 | 0 | 0 | 0 | "This place has… | "2016-07-25 04:… |
| "I90lP6oPICTkrh… | "1UAb3zZQeGX6fz… | "_ab50qdWOk0DdB… | 5.0 | 0 | 0 | 0 | "OH MY!! A must… | "2016-12-19 20:… |
| "469eAl2fB069YT… | "p2kXD3gNu3N776… | "_ab50qdWOk0DdB… | 5.0 | 0 | 0 | 0 | "The fried seaf… | "2018-08-23 20:… |
| "aPpHBDs7Jiiq0s… | "7cDhfvTSH1wTxE… | "_ab50qdWOk0DdB… | 5.0 | 0 | 0 | 0 | "I love this pl… | "2013-06-24 18:… |
| "k9OG5kA5ebruSx… | "7QTh-fkw9Nr2lO… | "_ab50qdWOk0DdB… | 3.0 | 0 | 0 | 0 | "Loved the char… | "2010-10-06 08:… |
Data Analysis: User Data
In the original document I also started an investigation of user-data to validate if we could find bots in the data, I did this by the following code snippets:
df_user = pl.scan_ndjson("/kaggle/input/yelp-dataset/yelp_academic_dataset_user.json")
df_user.limit(3).collect()
low_rating = pl.col("average_stars") <= 1.5
many_reviews = pl.col("review_count") > 5
df_user.filter(low_rating & many_reviews).limit(3).collect(streaming=True)
high_rating = pl.col("average_stars") >= 5
df_user.filter(high_rating & many_reviews).limit(3).collect(streaming=True)This show-cases the modularity of polars to build queries, which is awesome!
Unfortunately I didn’t have the time to dive deeper, as such I removed outputs too.
Appendix B: Additional Tasks
Back to the actual action!
As I said I had a few different ideas. If we’d do a simple classification (e.g. Stars) I’d start with the following approach:
- TF-IDF + SVC
- Embeddings + SVC (e.g. BERT or GloVe)
- RNN’s (e.g. ULMFit)
- LLM (e.g. BERT)
The models grows in complexity as we move down the list and the preprocessing would change.
TF-IDF and SVC requries removal of Stopwords and using stemming or lemmatization to reduce the feature-space/dimensionality of data.
Most likely TF-IDF would yield great results, but potentially we’d have to upgrade into RNN’s or LLM’s.
An LLM is great in the way that we only need to remove outliers, otherwise no preprocessing required because it finds the semantic meaning of a review. As mentioned though this wasn’t implemented because of low value.
Task: Keyword Extraction
Extracting keywords sometimes yield very interesting results, sometimes not.
Reviews should have some things in common, such as opening hours, pricing and taste.
I see two (2) simple approaches:
- Algorithmically using something like
yakethat uses statistical attributes - Using LLM/GPT with prompt-engineering
Because I don’t fully focus on this task I use an algorithmic approach where I sample 10k random reviews.
import yake
all_reviews = ' '.join(df_review_all.select("text").take_every(25_000).limit(10_000).collect(streaming=True)["text"])
kw_extractor = yake.KeywordExtractor(lan="en",
n=3,
dedupLim=0.9,
dedupFunc="seqm",
windowsSize=1,
top=20)
keywords = kw_extractor.extract_keywords(all_reviews)
keywords[('hours from beginning', 0.020546851659972578),
('beginning to end', 0.020546851659972578),
('decide to eat', 0.025264111118808684),
('hours', 0.12825615159841589),
('end', 0.12825615159841589),
('decide', 0.15697631639850676),
('eat', 0.15697631639850676),
('aware', 0.15697631639850676),
('beginning', 0.15697631639850676),
('multiple times', 0.19363023454619058),
('long', 0.24804685754303113),
('long time', 0.25772883998254764),
('bad experience', 0.3044312085113188),
('food is good', 0.34348020376910804),
('long waiting', 0.36025637540118816),
('multiple', 0.3927272948795476),
('times', 0.41305917611316423),
('time', 0.41305917611316423),
('good', 0.47708038648245615),
('experience', 0.48107913691662785)]My hypothesis seems to hold! This is interesting and I believe we could move forward with this track, but for now I’ll move back into the other topics I approached.
Anyhow, time, experience and hours seems to be contestion of most important keyword!
Task: Find Topic Themes by Stars
Let’s see if we can find a common thematic between different stars on reviews by embedding our sentences and coloring by stars. First we need to figure out how many stars we have and how to move them.
def get_star_perc(df: pl.DataFrame):
return (df
.groupby("stars")
.count()
.with_columns(perc=pl.col("count") / pl.sum("count")))
lhs = get_star_perc(df_review)
rhs = get_star_perc(df_review_all).collect() # lazy.collect()
df_stars = lhs.join(rhs, on="stars")
df_stars = df_stars.select(["stars", pl.col("perc").alias("single_restaurant"), pl.col("perc_right").alias("sample_of_all")])
df_stars.sort("stars").to_pandas().plot.bar(x="stars", y=["single_restaurant", "sample_of_all"])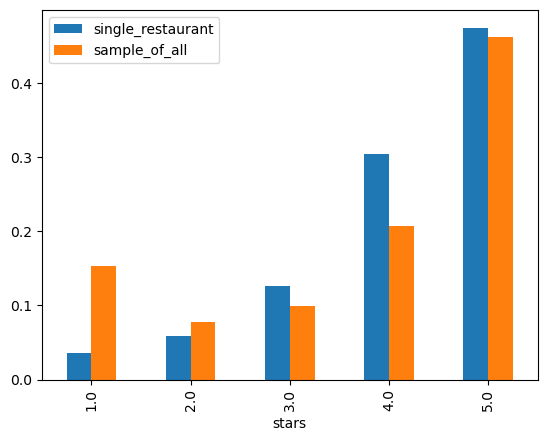
We can clearly see that 1-star vs 4-star is unbalanced in the two dataset, the selected restaurant is having a lot more positivity attached than the general theme!
Embedding and thematics of ‘Stars’
Let’s review if there’s a simple theme to find using a basic embedding.
BPEmb is built on Byte-Pair Encoding and gives us Subword Embeddings in 275 (!) languages. It’s really great!
The creators share that it has the same performance using a 11MB file as a 6GB FastText-file.
from bpemb import BPEmb
bpemb_en = BPEmb(lang="en", dim=50) # low dimensionality to keep memory lowdownloading https://nlp.h-its.org/bpemb/en/en.wiki.bpe.vs10000.model100%|██████████| 400869/400869 [00:01<00:00, 358780.98B/s]downloading https://nlp.h-its.org/bpemb/en/en.wiki.bpe.vs10000.d50.w2v.bin.tar.gz100%|██████████| 1924908/1924908 [00:01<00:00, 1139119.63B/s]import numpy as np
def simple_avg_embeddings(text: str) -> np.array:
"""Would prefer to do USif or a similar more advanced sentence embedding"""
return np.mean(np.array(bpemb_en.embed(text)), 0)
simple_avg_embeddings("hello world")array([-3.77557367e-01, -3.78913283e-02, 5.37733175e-03, 3.01063985e-01,
1.22853994e-01, -1.16067998e-01, -1.96355328e-01, 2.24513650e-01,
1.52528659e-01, 1.50793329e-01, -1.32929996e-01, 2.45790675e-01,
2.88366582e-02, 1.45034671e-01, -4.60664422e-04, -2.41063997e-01,
1.13379657e-01, 2.01904342e-01, -1.51245669e-01, 7.02560022e-02,
1.38975337e-01, 1.45603001e-01, 1.67376995e-01, -3.75553995e-01,
8.85626674e-02, -1.05586670e-01, -1.04991339e-01, 1.67683307e-02,
-3.47706318e-01, 7.66509920e-02, 4.86541659e-01, -5.46200061e-03,
3.15280318e-01, -1.35019004e-01, -8.56519938e-02, 2.60051340e-01,
-1.04355663e-01, -3.84614974e-01, -6.59673288e-02, 1.19441666e-01,
-1.55402347e-01, -3.78577620e-01, 1.48357674e-01, 8.83906707e-02,
-6.47209957e-02, 3.22343677e-01, -3.02187651e-01, 1.48631334e-01,
2.30536342e-01, 1.86697006e-01], dtype=float32)df_review = df_review.with_columns(pl.col("text").apply(simple_avg_embeddings).alias("emb"))df_review.head(1)
shape: (1, 10)
| review_id | user_id | business_id | stars | useful | funny | cool | text | date | emb |
|---|---|---|---|---|---|---|---|---|---|
| str | str | str | f64 | i64 | i64 | i64 | str | str | object |
| "vHLTOsdILT7xgT... | "417HF4q8ynnWtu... | "_ab50qdWOk0DdB... | 5.0 | 0 | 0 | 0 | "This place has... | "2016-07-25 04:... | [-0.19162591 0.15060863 -0.078258 0.15518992 -0.12187849 0.11793589 -0.07643473 0.1317546 -0.1048084 -0.03124337 0.05094633 0.12367388 -0.00363489 -0.2647824 -0.06410762 0.04014542 0.07875077 -0.278056 0.00739759 -0.07181404 -0.04439502 0.01154997 0.03282384 -0.0340792 0.15889876 0.0838833 0.01600609 0.10613644 -0.31489417 0.03023791 0.10793628 -0.03118962 -0.19363998 0.20003138 -0.15389948 0.03025126 0.00232455 -0.10293934 0.05226081 0.06783426 -0.22778073 0.12673096 -0.18912943 0.25403503 0.22409369 0.01150362 -0.01854107 0.07260673 0.21675265 0.22890206] |
from sklearn.manifold import TSNE
tsne = TSNE()
result = tsne.fit_transform(np.array(df_review["emb"].to_list()))
del tsne
result/opt/conda/lib/python3.7/site-packages/sklearn/manifold/_t_sne.py:783: FutureWarning: The default initialization in TSNE will change from 'random' to 'pca' in 1.2.
FutureWarning,
/opt/conda/lib/python3.7/site-packages/sklearn/manifold/_t_sne.py:793: FutureWarning: The default learning rate in TSNE will change from 200.0 to 'auto' in 1.2.
FutureWarning,array([[ 10.191183 , -30.586485 ],
[ 50.212452 , -0.08102626],
[-23.563566 , -43.164993 ],
...,
[ -6.7240796 , 31.503109 ],
[ 26.029615 , 34.519146 ],
[ 38.290615 , 9.39187 ]], dtype=float32)import plotly.express as px
import pandas as pd
df_tsne = pd.DataFrame({"x": result[:,0], "y": result[:,1], "rating": df_review["stars"].cast(str).to_list()})
del result
px.scatter(df_tsne, x="x", y="y", color="rating")del df_tsneThis didn’t work out either really…
How about a LLM?
from sentence_transformers import SentenceTransformer
from IPython.display import clear_output
model = SentenceTransformer('all-MiniLM-L6-v2')
clear_output()encoding = model.encode(df_review["text"].to_list())
del model
tsne = TSNE()
tsne_enc = tsne.fit_transform(encoding)
del encodingdf_tsne = pd.DataFrame({"x": tsne_enc[:,0], "y": tsne_enc[:,1], "rating": df_review["stars"].cast(str).to_list()})
del tsne_enc
px.scatter(df_tsne, x="x", y="y", color="rating")Sentence BERT produces a bit better result, we can see that 1-star reviews clusters nicely by themself.
The other reviews are pretty similar.
How to improve the clustering
Make use of a smarter tooling which builds topics rather than raw clustering based on embeddings. Tools like Bertopic, Toc2Vec and simply sentence-transformers (script) can achieve this in a simple manner.